Mortgage Denial Analysis: LA vs. CA
For this project in my Financial Analytics class, I worked on a team to analyze mortgage denial patterns in Louisiana and California using public lending data. Our goal was to predict loan approval outcomes and explore how demographic features impacted those predictions across states.
We started by cleaning and preparing the data: dropping rows with missing income values, removing empty columns, scaling numerical variables like loan amount and income, and one-hot encoding categorical demographics. We then defined a binary target variable where 1 indicated a denied loan application and 0 indicated approval.
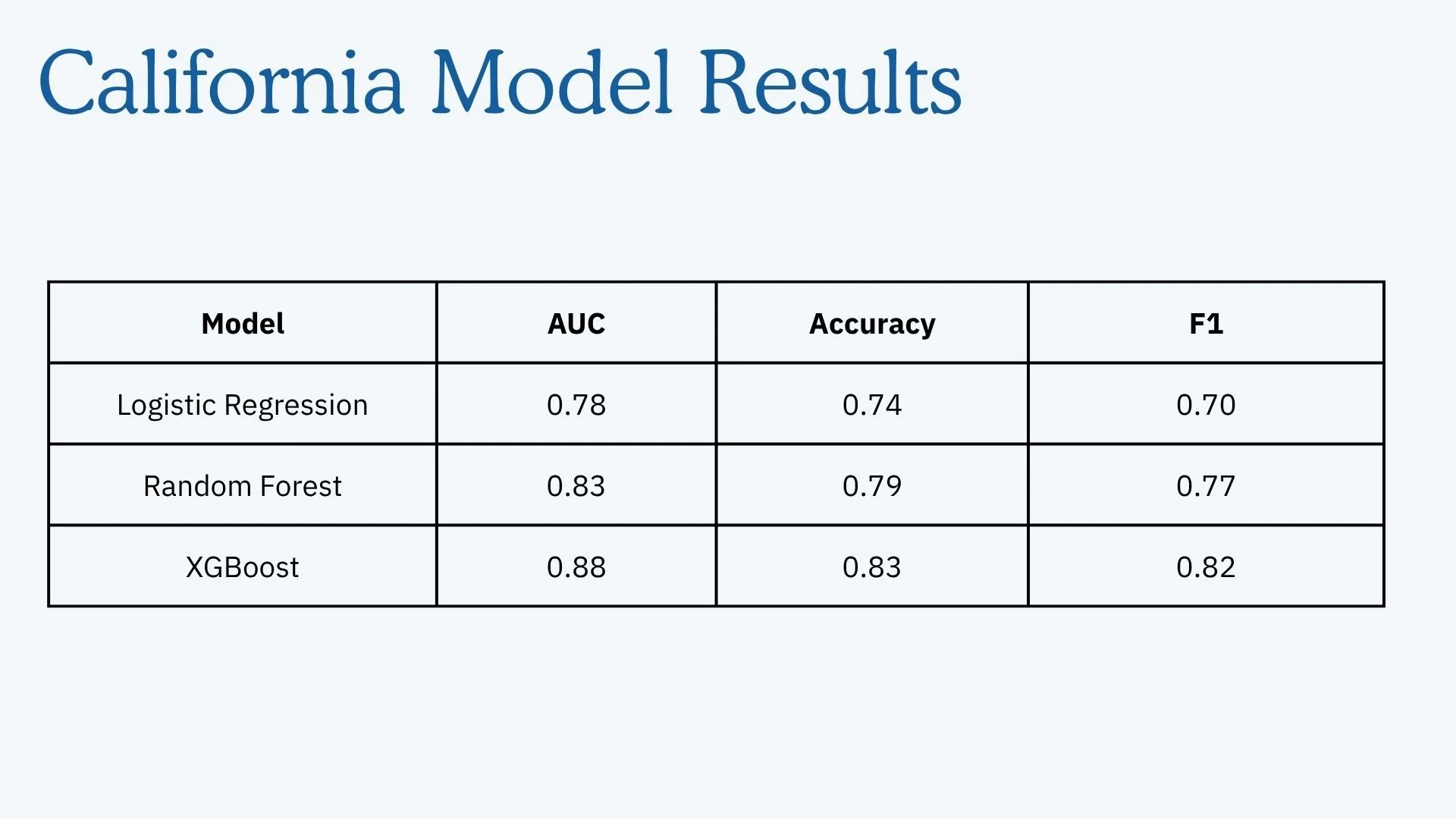
Using this cleaned dataset, we trained three models for each state: Logistic Regression, Random Forest, and XGBoost. XGBoost consistently outperformed the others, achieving an F1 score of 0.81 for Louisiana and 0.82 for California. We used LIME to interpret model outputs and identify top predictors of denial and approval.
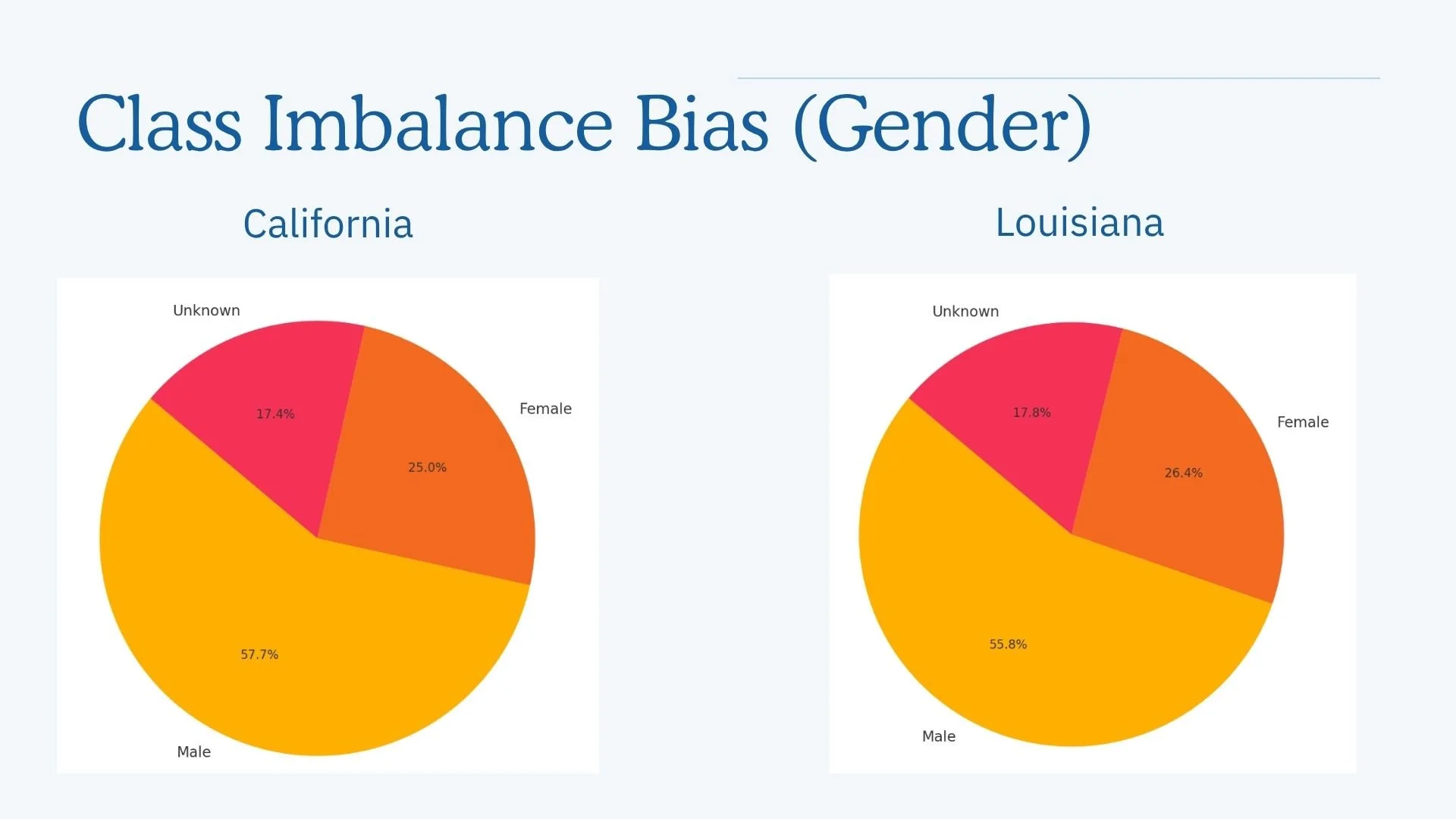
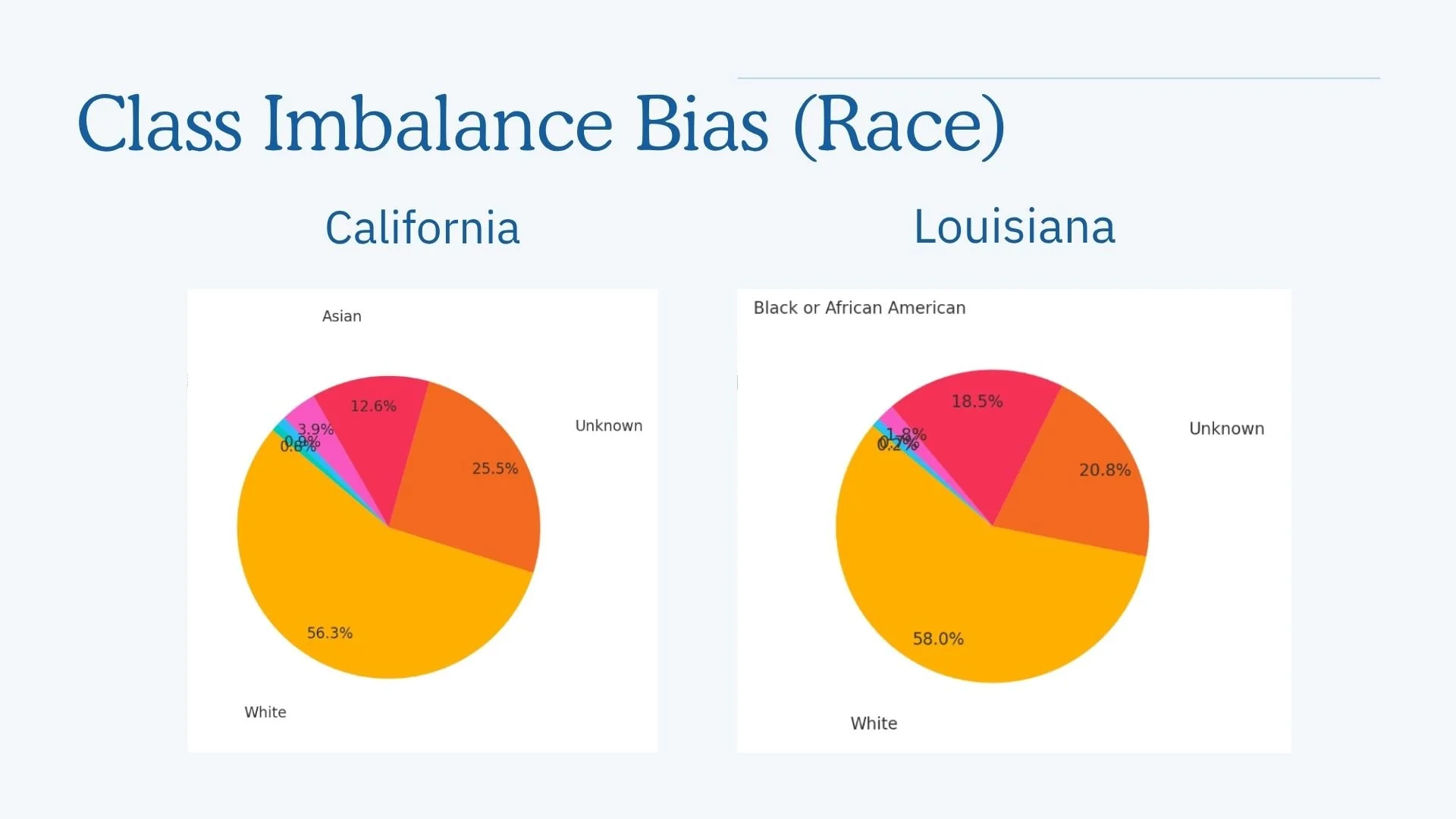
Across both states, race and gender were significant factors. Applications listing Black or African American race and male gender were more likely to be denied, while White or Asian applicants had higher predicted approval rates. These patterns point toward systemic disparities that persisted even after controlling for income and loan amount.
One of the biggest takeaways for me was how powerful and interpretable machine learning methods can be when paired with tools like LIME. It also reinforced the importance of checking for bias; our models revealed embedded disparities that a raw accuracy score alone wouldn’t catch.
This project sharpened my skills in classification modeling, data preparation, and fairness-aware ML. It also deepened my understanding of how to responsibly analyze demographic data in high-stakes contexts like lending. I have attached the presentation below if you’d like to see how it all came together!